马上注册,下载更多AI资源软件
您需要 登录 才可以下载或查看,没有账号?立即注册
×
VisoMaster V9版 - 一款强大专业的AI换脸软件,一键实现图片/视频/直播实时换脸 支持批量 本地一键整合包下 ...

VisoMaster 是一款全新的功能强大且易于使用的AI换脸工具,用于在图像和视频中进行换脸和编辑(支持AI直播实时换脸)。它利用人工智能技术,只需少量操作即可生成自然效果,非常适合普通用户和专业人士使用。
VisoMaster 由原Rope直播版项目两位核心开发大佬Alucard24和argenspin基于PySide在Rope直播版基础上的重写版,继承了大部分Rope直播版的常用功能,并将由两位大佬定期更新和维护,期待未来更多更强大的功能。(当前已停更)
今天分享的 VisoMaster V9版(基于社区大佬改良的 VisoMaster-Fusion版V3.61),因是本站发布的第九个版本,故命名为V9版。V9版本基于最新的Torch框架和CUDA完全重新构建,更轻更快!
VisoMaster-Fusion版包含了原始版本的所有的功能,并集成了来自社区模组的重大增强。
比如VR模式、REF-LDM 去噪器、任务管理器(批量换脸)、图像批量处理、Xseg 嘴部蒙版、蒙版纹理传输以及多项实验性功能等,使其功能更加完善和强大。
该版本新增更多精细的参数和功能设置,尤其适合专业用户使用,更多参数的调教,带来更丰富的换脸体验。新手(尤其是没有使用过VisoMaster老版的用户)也可以使用默认配置使用基础功能。
详细功能列表
人脸交换:
支持多种面部替换模型
兼容 DeepFaceLab 训练的模型(DFM)
高级多面部替换,改进了蒙版(遮挡/分割集成用于嘴部和面部)
"仅替换最佳匹配"逻辑,在多面部场景中产生更干净的结果
适用于所有流行的面部检测器和关键点检测器
表情恢复器:将原始表情转移到替换的面部
恢复与增强:
面部恢复:支持流行的上采样模型,包括新添加的 GFPGAN-1024
ReF-LDM 滤波器:一种强大的基于参考的 U-Net 滤波器,用于清理和增强面部质量,可选择在其他恢复器之前或之后应用
高级纹理迁移:提供多种模式迁移纹理细节
自动色彩迁移:通过"测试蒙版"功能提升色彩匹配,实现更精确和稳定的结果
自动修复融合:智能将修复的面部融合回原始场景
任务管理器与批量处理:
可停靠界面:通过一个简单、集成的部件管理所有您的任务
保存/加载任务:将整个工作区状态(模型、设置、人脸)保存为任务文件
自动批量处理:排队多个任务,单击一次即可全部处理
分段录制:设置多个开始和结束标记,将视频的不同部分渲染并组合成一个最终输出
自定义文件命名:可选择使用作业名称作为输出视频文件
其他强大功能:
VR180 模式:处理和交换半球形 VR 视频中的面部
虚拟摄像机流:将处理后的帧发送到 OBS、Zoom 等软件
实时预览:在保存前实时查看处理后的视频
人脸嵌入:使用多张源人脸以获得更高的准确性和相似度
通过网络摄像头实时换脸
改进的用户界面:按住鼠标右键平移预览窗口,使用 Shift 键批量选择输入人脸,并从多个新主题中选择
视频标记:按帧调整设置以获得精确结果
TensorRT 支持:利用支持的 GPU 进行超快速处理
V9版更新日志:
执行重构:确保质量、提升性能,并修复用户体验方面的问题。
从 CUDA 12.9 更新到 13.x 版本,更轻更快。
PerformRecast——面部表情恢复器(新功能):这是一个新的模块,能够恢复或转移面部表情到新的结果上,同时具备较高的稳定性、性能优化以及用户体验上的改进。
DFL XSeg 面部障碍物防护功能:XSeg 遮罩现在能够防止面部被障碍物挡住,同时还增加了 XSeg 颜色修正功能。
相似度与漂移的改进:解决了漂移问题,增强了相似度的控制能力,同时调整了关键点的替换机制,使得替换过程更加稳定且一致。
为 口腔贴合与对齐 参数提供舌部保护:在口腔适配和对齐过程中,防止舌头受到挤压或变形。
网络摄像头与用户界面优化:已修复了网络摄像头显示问题;现在,嵌入的卡片按钮名称在悬停时不会抢走用户的注意力。
摄像头视线锁定功能——这是“帧编辑”模式中的新功能。该功能支持对每只眼睛的视线进行独立计算,并能进行后续的平滑处理。
多 GPU 选择——当安装了多个 GPU 时,可从中选择某个特定的 GPU 来使用。这一设置会一致地应用于所有的检测器、交换器、修复器、增强器、编辑器以及 DFM 模型中。
自动嘴巴效果升级:取消了“隐藏上排牙齿”的选项(通过调整口腔内部遮罩的亮度,仍可让上排牙齿可见),同时新增了“显示嘴巴轮廓”的调试功能。
口型匹配与咬合对齐——现在,被替换的嘴巴可以继承原始模型的咬合方式,从而实现更自然的过渡效果。
网络摄像头——解决了与加载过程及运行时的相关问题。
多个Bug修复
V8版本更新
本次发布是对 VisoMaster Fusion 的重大改进,带来了新功能、显著的性能提升、广泛的错误修复以及整体更加完善的用户界面。感谢所有贡献者!
更新了 CUDA 12.9 的 GPU 运行时堆栈,支持更新的 PyTorch、ONNX Runtime、TensorRT 和 cuDNN。
改进了 TensorRT 的处理、引擎缓存、模型加载、回退行为以及更多模型的 FP16 推理。
添加了 ByteTrack 人脸跟踪,以在运动、遮挡、剪辑和多人脸场景中实现更稳定的人脸识别。
添加了视频问题审查工具,用于扫描问题帧、在不同问题之间跳转、丢弃/恢复帧以及从渲染输出中排除丢弃的帧。
扩展了 VR180 处理,支持单眼模式、瓦片人脸检测、可调节的裁剪 FOV、可选的裁剪分辨率以及拼接/检测修复。
添加了人脸年龄控制以及由口部动作驱动的自动口部表情控制。
扩展了人脸表情恢复器,支持简单/高级模式、区域控制、注视/眼睑调节、归一化和微表情设置。
改进了口部遮罩、混合、降噪、输出处理、录制、批量处理和 Job Manager 稳定性。
添加了全局输入缩放和改进的输出位置控制,以实现更灵活的图像和视频工作流程。
优化了界面,包括可折叠参数部分、Theatre Mode 改进、布局恢复修复和新主题。
通过启动器添加了 ONNX 模型优化工具。
添加了新文档,包括快速入门指南和扩展的用户手册。
添加了广泛的基于 pytest 的测试套件。
修复了性能、缓存、播放、音频同步、VR180、检测/跟踪和 UI 方面的许多问题。
V8版Bug修复:
修复了搜索延迟问题;添加了 FrameWorkerDelayDecimalSlider (0–3 秒)以防止在搜索期间 GPU 过载
修复了播放缓冲问题和无界显示帧队列导致的内存膨胀
修复了在切换目标视频时出现的过期预览帧
通过无关编解码器的方法修复了跳帧音频重建问题
修复了默认录制模式下音频分段问题
修复了音频合并清理和时序问题
使跳过帧的音频重建完全同步感知
修复了检测器输入尺寸读取问题(现在使用模型声明的输入形状,而不是硬编码值)
修复了 ByteTrack + 表情恢复器的交互问题
UI及多个功能优化。
V7版更新日志:
用户界面:
分别为“目标视频/图像”、“输入人脸”、“任务”设置独立的组件面板,每个面板都有显示/隐藏切换功能
“人脸”面板的切换将主要功能放在“控制选项”选项卡上
跟踪“目标视频/图像”的滤镜
添加了"移动到回收站"和"打开文件位置"到媒体'目标视频/图像'和'输入面部'
添加了新的主题:True-Dark、Solarized-Dark、Solarized-Light、Dracula、Nord、Gruvbox
改进了'控制选项'标签中参数和控制排序及放置,并添加了分类
添加了包含两个帮助面板的"帮助"菜单
增加了完整的"嵌入编辑器"
在工作室的 .json 文件中保存和恢复"主窗口"和"小部件"状态
模型:
为 InstyleSwapper256 模型 A、B 和 C 添加了 512 分辨率
为差分和纹理传递添加了VGG_Combo_relu3模型
添加了 GFPGAN-1024 修复模型
添加了 REF-LDM 模型作为去噪器
改进:
Inswapper128 自动分辨率
交换前锐度滑块
面部解析选项可在管道末尾运行,并可通过切换仅在嘴部内部区域进行解析
新的差分方法
改进了自动颜色传输,增加了在管道末尾进行二次传递的功能
面部编辑器流程位置选择,以增加控制
面部修复器“自动修复”功能,自动调整混合值和清晰度,并在末尾添加面部修复器 2 切换
面部表情修复器重新设计,将眼睛和嘴唇选项分开进行精细调整,添加了归一化眼睛(防止“鱼眼”),添加了相对位置切换,并添加了流程位置选择
V7版新功能:
支持 VR 视频
任务管理器
嵌入编辑器
图像批量处理
Xseg 口部蒙版,用于增强口部区域的蒙版控制
通过蒙版操作进行纹理传输,以增强真实感,用于精细调整
MPEG 压缩伪影模拟
REF-LDM 去噪器,包含 K/V 图提取功能、单步和完整恢复模式、三种管道传输选项
录制时保持控件激活选项
播放时音频功能,带音量和延迟滑块
播放缓冲选项
视频录制选项,帧调整为 1920*1080,录制后打开输出文件夹,HDR 编码(CPU),FFMPEG 控件
使用开始/停止位置标记分段录制
仅一次交换输入人脸功能,以防止场景中存在多个相似人脸时发生错误的人脸交换
自动加载上次工作空间
完整预设功能,用于保存和应用每张脸的参数以及全局控制
使用教程:(建议N卡,显存6G起,已内置CUDA和TensorRT,无需额外安装环境,真正解压即用)
整体和Rope直播版操作类似
视频教程:https://www.toutiao.com/video/7488660349063856691/
https://www.toutiao.com/video/7469732364723225123
如何使用DFM模型换脸:
首先将DFM模型文件拷贝到model_assets\dfm_models目录下
然后右侧控制选项切换到“人脸交换”,换脸模型下拉,切换到DeepFaceLive(DFM),即可找到你的DFM模型,切换到DFM模型,点击交换人脸即可。
注.dfm模型不要用中文以及特殊符号命名,使用dfm模型需配合DFL Xseg遮罩选项。
如何加载摄像头:
点击“目标媒体”栏下的“目标媒体过滤器”,如下图
勾选 摄像机 即可
如需要了解更多详细参数设置和作用域,请点击软件“帮助”菜单下的“快速入门指南”和“用户手册”,我在官方文档上做了汉化翻译,方便国内用户查阅。
默认设备为 TensorRT,使用 TensorRT 首次会生成缓存文件(只要加载新模型就会触发),出现”假死“状态,并非真实卡死,而是在后台生成缓存,需要一段时间,等待完成即可
软件目录结构
📂 app/
📂 model_assets/
├── 📂 models/
│ ├── 📂 dfm_models/
│ │ └──男模.dfm
│ │ └──女模.dfm
│ ├── 📂 liveportrait_onnx/
│ ├── 📂 ref-ldm_embedding/
│ │ └── flymy_realism.safetensors
📂 deepface/
......
下载地址:
夸克网盘:
🔒付费内容 游客, 上上宾会员 可免费下载该资源, 点此开通上上宾 免费下载全站99%的付费资源。或单独支付 199碎银 下载该资源
百度网盘:
🔒付费内容 游客, 上上宾会员 可免费下载该资源, 点此开通上上宾 免费下载全站99%的付费资源。或单独支付 199碎银 下载该资源
| 









 发表于
发表于 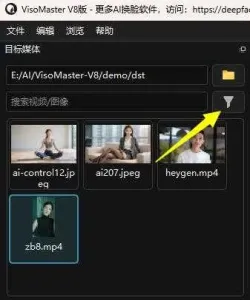
 发表于
发表于 
 发表于
发表于