马上注册,下载更多AI资源软件
您需要 登录 才可以下载或查看,没有账号?立即注册
×
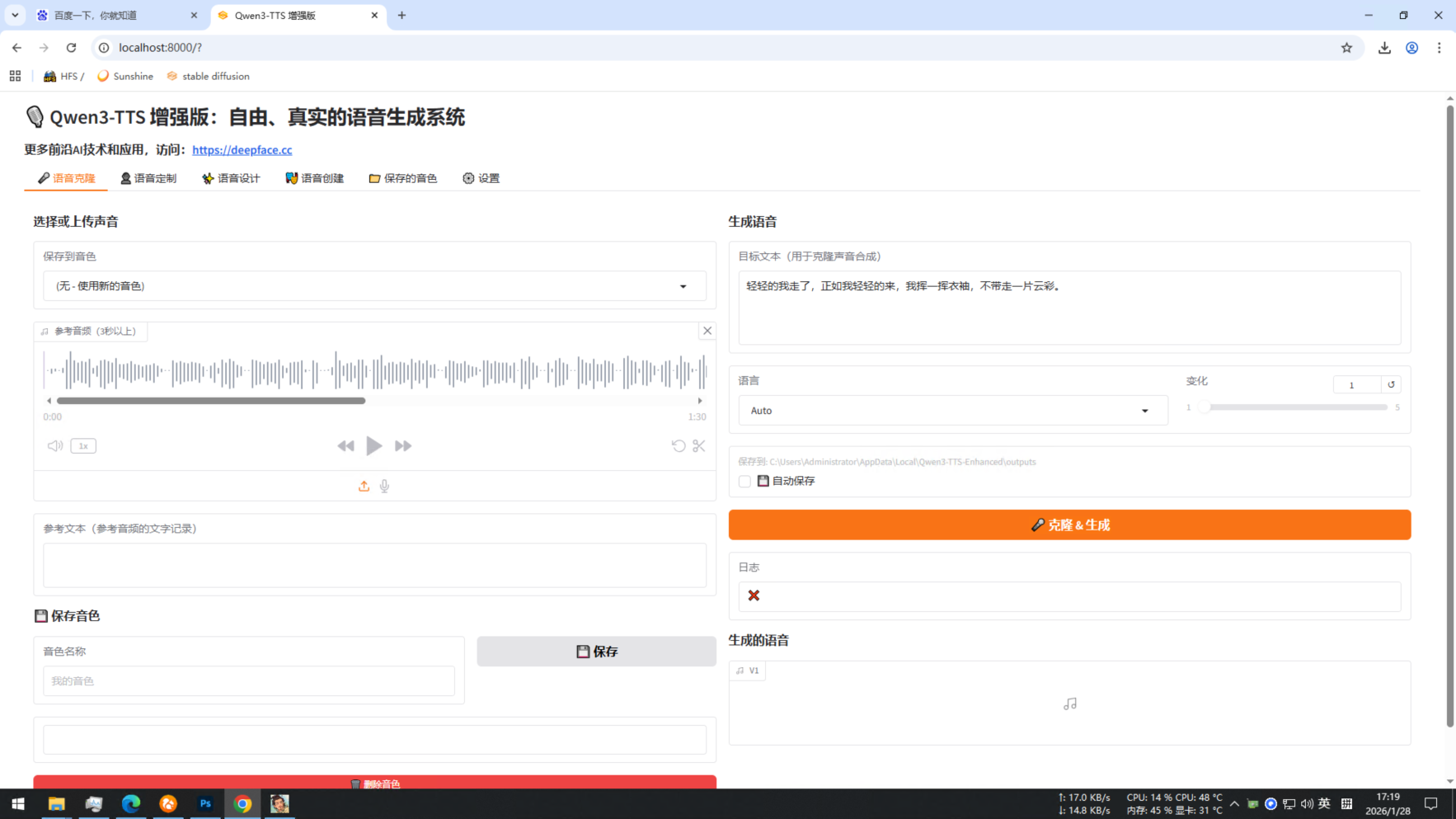
Qwen3-TTS V2版 - 一句话指挥AI配音 自由定制你的专属声音 新增音色保存 音色创建 支持50系显卡 一键整合 ...

Qwen3-TTS 是阿里云团队推出的一个开源语音合成(Text-to-Speech, TTS)工具,它能把文字快速、自然地转成语音,还能定制声音风格、克隆声音,甚至支持实时对话场景。
Qwen3-TTS 把“做语音”这件事从专业配音员的活儿,变成了“会打字就会做”的程度,而且效果已经非常接近专业水准了,它的特点是声音逼真、可控、支持多语言,并且延迟极低,支持仅用 3 秒音频就能生动克隆声音、通过自然语言一句话 自由设计/控制音色情绪风格、超低延迟(最快 97ms)流式实时生成,支持 10 种语言 + 多方言,整体实现稳定、自然、富有表现力的语音合成。
今天分享的 Qwen3-TTS V2版(Qwen3-TTS 增强版)基于社区大佬NeoKazuya开源的版本打包支持,该版本保留了官方原版的三个功能外,新增音色保存功能,还新增了一个新的功能,即支持上传多个音色融合成一个新的音色。我在原版的基础上修复了几处bug,并新增了Flash_Attn加速,自动检查显卡是否支持加速,优先启用加速提升生成速度;新增了多出显存优化和回退机制,防止多次生成导致报显存错误。
核心亮点
一句话就能自定义声音风格(自然语言控制)
你可以直接写:“用温柔的御姐音,语速稍慢,带一点撒娇的感觉读这段话” AI就能尽量按你的描述来念,真的很像在跟AI导演配音。
3秒就能克隆你的声音(超快语音克隆)
只给你3秒音频,它就能模仿你的声音说话,克隆效果生动、自然,不像以前那种机器人感很重。
可以凭空“捏”一个新声音(自由语音设计)
不需要参考音频,你直接描述:“20岁元气少女声,带一点台湾腔”或者“低沉磁性大叔音,像Morgan Freeman那种感觉”,它就能试着生成。
延迟超低,能边想边说(流式生成)
最快97毫秒就能出声,非常适合做实时对话的AI助手、直播念评论、实时翻译配音等场景。
支持10种语言 + 很多方言
中、英、日、韩、德、法、西、俄、葡、意等。中文还包含普通话+粤语+闽南语+四川话+东北话+天津话等很多地方口音 音色超级丰富 官方自带几十种高质量预设音色(男女老少、不同性格、不同语言组合都有),直接挑着用就很好听。
应用领域
智能客服与语音助手 在客服系统或智能音箱中,提供自然流畅的语音回复,提升用户体验。
教育与培训 用于在线课程、语言学习软件,生成多语言讲解或练习音频。
内容创作与配音 视频博主、播客制作者可以快速生成不同风格的配音,无需真人录音。
游戏与虚拟角色 为游戏角色或虚拟人提供个性化声音,支持情绪化表达,让角色更真实。
无障碍应用 帮助视障人士通过文字转语音获取信息,提升信息可达性。
实时互动场景 如直播、在线会议、虚拟客服,利用低延迟语音生成实现即时交流。
使用教程:(建议N卡,显存6G起,支持50系显卡)
包含三种语音场景
1、语音设计:可以根据文字描述设计声音,比如“温柔女声”“年轻男声”,甚至能创造全新的声音角色
2、语音克隆:只需几秒钟的音频样本,就能快速复制某个人的声音,用来生成新的语音内容
3、语音定制:多种预设音色的文本转语音,支持定制情感
默认使用质量更高的1.7B模型,建议显卡显存8G起,显存低于8G可以使用上个版本,支持更小的0.6B模型。
关于声音描述:比如目标文本 “哥哥,你回来啦,人家等了你好久好久了,要抱抱!”
提示词可以借助大模型,写出你要表达的情感,比如下面的描述:“体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果”
你也可以填写更多描述细节,比如男声女声,年龄等信息。
关于第二个“语音定制”标签,可以使用预置音色,议使用每位说话者的母语,以获得最佳质量。当然,每个说话者都可以说模型支持的任何语言。
以下是预置的几种音色介绍,大家可以根据需要选择:
Vivian 明亮、略带锋芒的年轻女性声音 中文
Serena 温暖、温柔的年轻女性声音 中文
Uncle_Fu 经验丰富的男性嗓音,音色低沉柔和 中文
Dylan 年轻的北京男性嗓音,音色清晰自然 汉语(北京方言)
Eric 活泼的成都男声,带着一丝沙哑明亮 中文(四川话)
Ryan 充满活力的男性声音,节奏感强劲 英语
Aiden 阳光的美国男声,中音清晰 英语
Ono_Anna 活泼的日本女性声音,音色轻盈灵巧 日语
Sohee 温暖的韩国女性声音,情感丰富 朝鲜语
下载地址:
UC网盘:https://drive.uc.cn/s/c02a35d92a4e4
下载主程序压缩包和模型(ckpts文件夹),解压主程序,并把ckpts文件夹移动到主程序目录下即可。
夸克网盘:
🔒付费内容 游客, 上上宾会员 可免费下载该资源, 点此开通上上宾 免费下载全站99%的付费资源。或单独支付 30碎银 下载该资源
百度网盘:
🔒付费内容 游客, 上上宾会员 可免费下载该资源, 点此开通上上宾 免费下载全站99%的付费资源。或单独支付 50碎银 下载该资源
| 









 发表于 2026-1-26 17:07:26
发表于 2026-1-26 17:07:26

 发表于 2026-1-26 18:59:27
发表于 2026-1-26 18:59:27
 发表于 2026-1-26 22:48:30
发表于 2026-1-26 22:48:30